Google的吴军研究员写了数学之美系列,其中有“余弦定律与新闻的分类”和”矩阵运算和文本处理中的分类问题“对自动分类、相似度、去重等相关问题原理作了介绍,并找到一些相关算法:
余弦定律与新闻的分类
Google 的新闻是自动分类和整理的。所谓新闻的分类无非是要把相似的新闻放到一类中。计算机其实读不懂新闻,它只能快速计算。这就要求我们设计一个算法来算出任意两篇新闻的相似性。为了做到这一点,我们需要想办法用一组数字来描述一篇新闻。
我们来看看怎样找一组数字,或者说一个向量来描述一篇新闻。回忆一下我们在“如何度量网页相关性” 一文中介绍的TF/IDF 的概念。对于一篇新闻中的所有实词,我们可以计算出它们的单文本词汇频率/逆文本频率值(TF/IDF)。不难想象,和新闻主题有关的那些实词频率高, TF/IDF 值很大。我们按照这些实词在词汇表的位置对它们的 TF/IDF 值排序。比如,词汇表有六万四千个词,分别为
单词编号 汉字词
——————
1 阿
2 啊
3 阿斗
4 阿姨
…
789 服装
….
64000 做作
在一篇新闻中,这 64,000 个词的 TF/IDF 值分别为
单词编号 TF/IDF 值
==============
1 0
2 0.0034
3 0
4 0.00052
5 0
…
789 0.034
…
64000 0.075
如果单词表中的某个次在新闻中没有出现,对应的值为零,那么这 64,000 个数,组成一个64,000维的向量。我们就用这个向量来代表这篇新闻,并成为新闻的特征向量。如果两篇新闻的特征向量相近,则对应的新闻内容相似,它们应当归在一类,反之亦然。
学过向量代数的人都知道,向量实际上是多维空间中有方向的线段。如果两个向量的方向一致,即夹角接近零,那么这两个向量就相近。而要确定两个向量方向是否一致,这就要用到余弦定理计算向量的夹角了。
当两条新闻向量夹角的余弦等于一时,这两条新闻完全重复(用这个办法可以删除重复的网页);当夹角的余弦接近于一时,两条新闻相似,从而可以归成一类;夹角的余弦越小,两条新闻越不相关。
矩阵运算和文本处理中的分类问题
分类的关键是计算相关性。我们首先对两个文本计算出它们的内容词,或者说实词的向量,然后求这两个向量的夹角。当这两个向量夹角为零时,新闻就相关;当它 们垂直或者说正交时,新闻则无关。当然,夹角的余弦等同于向量的内积。从理论上讲,这种算法非常好。但是计算时间特别长。通常,我们要处理的文章的数量都 很大,至少在百万篇以上,二次回标有非常长,比如说有五十万个词(包括人名地名产品名称等等)。如果想通过对一百万篇文章两篇两篇地成对比较,来找出所有 共同主题的文章,就要比较五千亿对文章。现在的计算机一秒钟最多可以比较一千对文章,完成这一百万篇文章相关性比较就需要十五年时间。注意,要真正完成文 章的分类还要反复重复上述计算。
在文本分类中,另一种办法是利用矩阵运算中的奇异值分解(Singular Value Decomposition,简称 SVD)。现在让我们来看看奇异值分解是怎么回事。首先,我们可以用一个大矩阵A来描述这一百万篇文章和五十万词的关联性。这个矩阵中,每一行对应一篇文 章,每一列对应一个词。
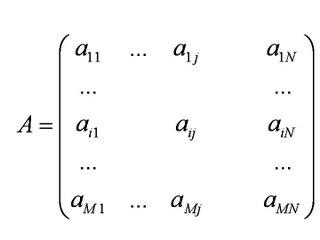
在上面的图中,M=1,000,000,N=500,000。第 i 行,第 j 列的元素,是字典中第 j 个词在第 i 篇文章中出现的加权词频(比如,TF/IDF)。读者可能已经注意到了,这个矩阵非常大,有一百万乘以五十万,即五千亿个元素。
奇 异值分解就是把上面这样一个大矩阵,分解成三个小矩阵相乘,如下图所示。比如把上面的例子中的矩阵分解成一个一百万乘以一百的矩阵X,一个一百乘以一百的 矩阵B,和一个一百乘以五十万的矩阵Y。这三个矩阵的元素总数加起来也不过1.5亿,仅仅是原来的三千分之一。相应的存储量和计算量都会小三个数量级以 上。
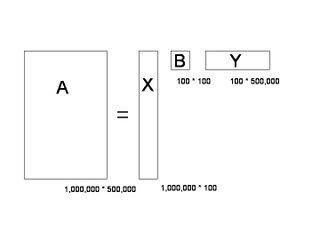
三个矩阵有非常清楚的物理含义。第一个矩阵X中的每一行表示意思相关的一类词,其中的每个非零元素表示这类词中每个词的重要性(或者说相关性),数值越大 越相关。最后一个矩阵Y中的每一列表示同一主题一类文章,其中每个元素表示这类文章中每篇文章的相关性。中间的矩阵则表示类词和文章雷之间的相关性。因 此,我们只要对关联矩阵A进行一次奇异值分解,w 我们就可以同时完成了近义词分类和文章的分类。(同时得到每类文章和每类词的相关性)。
现在剩下的唯一问题,就是如何用计算机进行奇异值分解。这时,线性代数中的许多概念,比如矩阵的特征值等等,以及数值分析的各种算法就统统用上了。在很长 时 间内,奇异值分解都无法并行处理。(虽然 Google 早就有了MapReduce 等并行计算的工具,但是由于奇异值分解很难拆成不相关子运算,即使在 Google 内部以前也无法利用并行计算的优势来分解矩阵。)最近,Google 中国的张智威博士和几个中国的工程师及实习生已经实现了奇异值分解的并行算法,我认为这是 Google 中国对世界的一个贡献。
相关算法
LSH, PartEnum, ALLPair and Google’s