1.Lucene的Score计算公式:
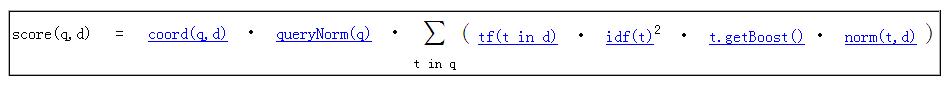
coord(q,d): 文档d中,q中命中的项数除以查询q的项总数
queryNorm(q): 只在不同query比较时影响score的normalizing因素

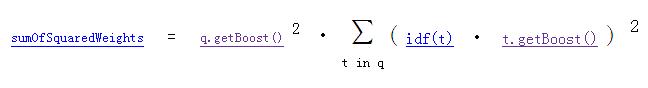
tf(t in d):单文本词汇频率,t在文档d中出现的次数除以d中所有的项总数的平方根
![]()
idf(t):逆文本频率指数,log(numDocs/docFreq+1)+1.0

If the document has multiple fields with the same name, all their boosts are multiplied together
比如:
doc: 1,000,000
q: term1 term2 term3
doc1: 200terms, 2个t1,1个t2,0个t3
…
t1: 在100个doc中出现
t2: 在50个doc中出现
t3: 在200个doc中出现
2/200 * (sqrt(2/200)*(1+log(1000000/(100+1))/
要点:
查询词在一个 Document 中的位置并不重要。
如果一个 Document 中含有该查询词的次数越多,该得分越高。
一个命中document中,如果除了该查询词之外,其他的词越多,该得分越少。
不足:
查询精确度不好。
没有体现网页的重要性。
Lucene的得分算法, 不适合网页搜索。
2.网上流传的针对Web的改进的算法:
Score_d = k1 * OldScore + k2 * PrScore + k3 * ReScore + k4 * homePageScore
注:
Score_d: 记录d的得分。
OldScore: 由基础排序算法计算出的记录d的得分。
PrScore: 记录d的PageRank的得分。
ReScore: 记录d的二次检索的加分, ReScore = rescore + (hitNum – 1) * increment
homePageScore: 主页的加分
K1, K2, K3, K4为权重系数
PR(A) = (1 − d)/N + d(PR(T1)/C(T1) + … + PR(Tn)/C(Tn))
– PR(A) 页面A的PageRank
– PR(Ti) 超链接到页面A的Ti页面的PageRank
– C(Ti) 页面Ti的链向其它页面的超链接数
– d 阻尼系数(0,1之间)
– N 所有网页的总数
计算Pagerank的步骤如下:
1)所有网页的Pagerank得分值都赋初始值
2)遍历网页数据库。对于每一个页面,通过查找链接数据库,得到当前页面所有的链出页面。再将当前页面的Pagerank得分值平分给每个链出的页面。
3)重复步骤2,迭代多次,直至收敛。
在结果中检索又称为二次检索。 是在当前检索结果内进行的检索,主要作用是进一步精选文献。当检索结果太多,想从中精选出一部分时,可使用二次检索。
hitNum是网页点击数
increment是该单词每多出现一次所增加的“分数”
另外,对于网页,term属于某些标签内应该也加以权重,如加黑的,图片上方或者下方的,title内的,标题元素等,对于普通文档,term包含在标题,摘要内的,或文档开头的也应有加分。可以通过setBoost完成